
Hello, there! Dr. Rukundo is back. In today’s blog, we’re diving into the topic of identity and class – but not in the way you might think. While this might sound like something related to DEI or social segregation, we’re talking about the chemical and/or biological identity of materials that we work with every day. Whether it’s in food production, pharmaceuticals, nutraceuticals, or even the flavor industry, accurately identifying materials is key to ensuring product quality and safety and meeting user requirements.
The Sugar Dilemma: A Simple Illustration of Material Identification
Imagine you’re following a home recipe that calls for two cups of sugar, but you accidentally add salt instead. What happens? It’s a disaster, right? The taste will be completely off, and you might not even make it to the end of the recipe.
Now, think bigger – on an industrial scale. In food, pharmaceutical and chemical production, it’s not uncommon for ingredients to look nearly identical, even though they have very different chemical properties. Operators can struggle to differentiate between them visually. In such cases, the usual practice is to run tests to confirm the identity of the material in question. These tests can range from simple, rapid confirmatory tests to more complex, time-consuming analyses. Sometimes, the materials need to be sent out for third-party testing, which introduces delays, added costs, and potential disruptions to production.
That’s where Near Infrared (NIR) Spectroscopy comes in, and it’s a game changer.
NIR Spectroscopy: The Technology That “Saves the Day”
NIR Spectroscopy is based on the interaction of light from the infrared region of the electromagnetic spectrum with a material. When light is directed at a sample, part of it is absorbed, and the rest is either reflected or transmitted. The amount of light that is returned to the detector carries valuable information, which can be used to infer the chemical identity of the sample – based on known or reference data.
For this, qualitative classification (or cluster analysis) comes into play. By building a calibration model using NIR, we can predict the identity of routine samples based on subtle differences in their chemical structures. These differences might not be visually obvious, but NIR spectroscopy can detect them with remarkable precision.
Cluster Models and How They Work
To create a useful cluster model for material identification, we need representative samples from each sub-class within the product group. These are essentially clusters of related materials that, while similar, have distinct chemical profiles.

For instance, let’s consider a sugar cluster, with five different types of sugar: D(+) Glucose, Anhydrous, D(+) Glucose, Monohydrate, Mannitol, Sorbitol, and Saccharose. At first glance, these sugars look quite similar and might even taste alike. But chemically, they are distinct, and NIR – with the right model – can differentiate them. Identifying each of these sugars with reference laboratory methods would require complex laboratory methods, which could take hours or even days – resulting in costly delays.
With NIR, however, we can build a cluster model that separates these sugars into distinct groups. We could use BUCHI’s NIRFlex N-500 to scan representative samples from each of these sugar types and collect their unique spectral data. The N-500’s flexibility allows us to present the sample in a variety of ways, including Petri dishes, glass vials, fiber optic probes, or even transparent plastic bags – without ever needing to open the sample.
The Power of the BUCHI NIRFlex N-500 in Building Accurate Cluster Models
Once we have spectral data for each of the sugars, we can assign each sample its respective identity.

At first glance, the spectra may not clearly distinguish each sugar because there are some overlaps in the spectral data. But with chemometric tools compatible with the BUCHI N-500, we can build a robust cluster model that separates the sugars and identifies each one with high confidence.
Let’s break down how this works:
- We scan multiple representative samples from each sugar group using the N-500.
- The Buchi NIRCal software processes the spectra based on each sugar’s correct chemical identity to build a cluster model.
- The cluster model is then fine-tuned and validated, ensuring reliable results.
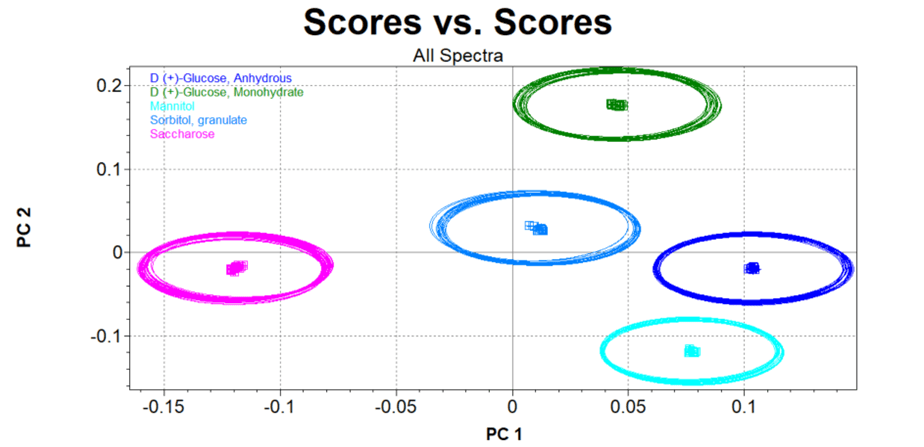
This allows us to instantly confirm the identity of any unknown sample. For example, let’s say a batch of sugar comes in, and you need to verify whether it’s D(+) Glucose, Monohydrate or another type. The N-500 quickly gives you an answer with minimal effort – helping you make better, faster decisions.
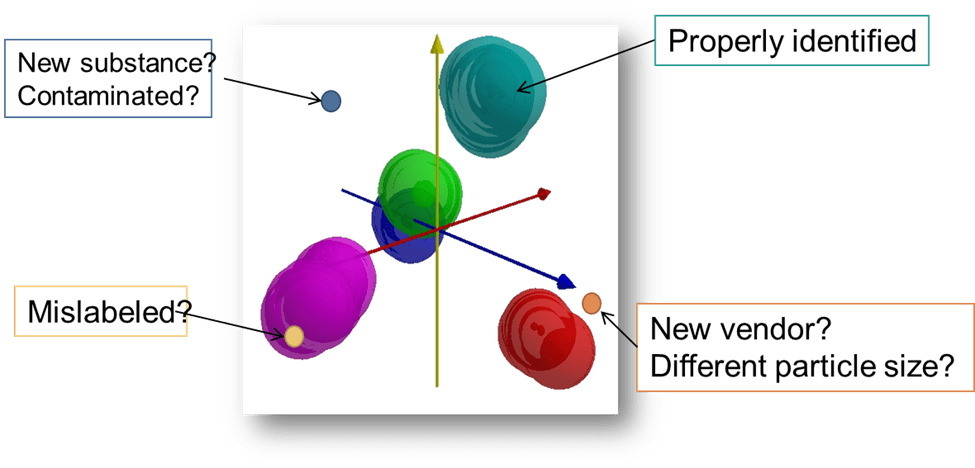
What Happens When a Sample Doesn’t Match?
There are several possibilities when running a sample through the cluster model:
- Proper Identification: The sample matches an existing group, like Mannitol. The model confirms its identity, and all is well.
- New Material Detected: The sample doesn’t fall into any of the pre-existing groups but is still within the overall cluster. This might indicate a new material, like an unknown type of sugar. In such cases, we can add this material to the cluster, expanding the model to include a sixth type of sugar.
- Similar But Different: The sample is close to one of the sub-groups but deviates slightly. This could indicate a different supplier or manufacturing process. Additional verification and testing can help confirm this.
- Unexpected Grouping: The sample is categorized in an entirely different group, which could be a sign of user error, such as incorrect labeling. This is a great opportunity to double-check the materials and their identities.
How Many Samples Do You Need for a Reliable Cluster Model?
Building a reliable cluster model requires enough representative samples for each material sub-class. There isn’t a strict rule for how many samples are enough, but a good starting point is at least three samples from five different lots of each material, with each sample being scanned three times. This will give you 45 separate spectra for each material, providing a solid foundation for a reliable model. If the materials come from different vendors or geographical regions, you should include additional samples to account for these variations.
BUCHI offers specialized training on how to build, manage, and maintain these chemometric models. With our dedicated support, you can keep your models updated as new materials are introduced or as your production processes evolve.
Beyond Qualitative Testing: The Power of Quantitative Calibration Models
The BUCHI NIRFlex N-500 isn’t just for qualitative classification. It also allows you to create quantitative calibration models for testing properties like moisture content, fat, protein, active ingredients, and other critical parameters. This versatility makes the N-500 an invaluable tool for a wide range of industries.
Conclusion
The ability to quickly and accurately identify the chemical identity of materials is crucial in many industries, from pharmaceuticals to food production and flavors. With the BUCHI N-500, you can implement powerful cluster models for qualitative testing, saving time and costs while ensuring that the materials used in your products meet the highest standards of quality.
If you’re interested in exploring this technology or implementing it into your workflow, don’t hesitate to reach out via our web form. We look forward to helping you enhance your material identification process with the BUCHI NIRFlex N-500! Once the unit has been identified, it is all too easy to estimate the revenue savings over time. In fact, the return on investment is so quick that I wonder why you don’t get it today, as opposed to waiting any longer.

Leave a comment